正文開始
接下來本篇文章,咱們要來說明所謂的『 I/O 』模型。
這個東西我當初看到也有點不太能理解,為什麼需要它,但後來理解以後發覺,你只要知道一個 http 請求 web server 是如何處理的,從 0 至 1,那這樣的話當你完全通了,就知道這為什麼會有這些模式。
本篇文章共分以下幾個章節 :
- 傳統的 Web Server 請求 I/O 處理與問題
- 非阻塞 I/O 模式核心 Reactor 模型。
- 一些常見的問題。
~ 重要備註 ~ 相信有不少人聽過阻塞、非阻塞、同步、非同步,也相信有些熟悉 linux 的友人,聽過它所提供的一些上述名詞的方法,但這裡要先說明,接下來的說有上述詞語,都是指『 應用層 』的表達,而不是『 業系統層 』的所提供的方法,除非有特別說明才是作業系統的。
傳統的 I/O 處理與問題
一個 I/O 請求進來要如何處理呢 ?
傳統的 I/O 請求處理
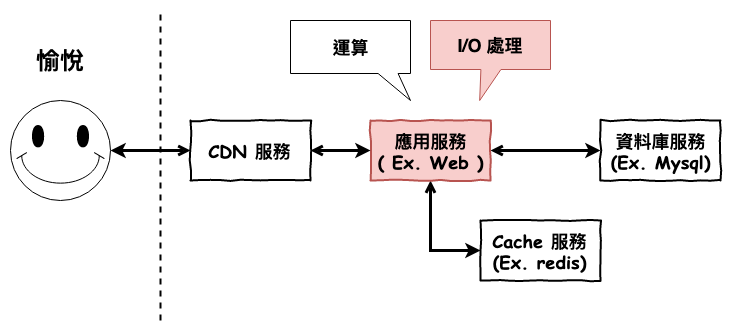
咱們這裡以 http server 處理請求時來當範例,如下圖所示,咱們以常見的 PHP + Apache 來看。如下圖 1 所示,每一個 http 請求都需要開啟一個或是使用一個進程來進行處理,這裡不是只有 http 請求會被阻塞,而是所有的 I/O ( ex. 網路請求、檔案讀取 ) 操作正常來說都是會被阻塞的。
 圖 1 : 傳統 http server 的請求處理
圖 1 : 傳統 http server 的請求處理
在高併發會有什麼問題呢 ?
基本上傳統的這個需要開多個進程或線程來處理 I/O 請求的會有以下幾個問題 :
高併發時會爆
主要會爆的原因有兩個,首先第一個是進程與線程的數量限制,而第二個是這樣會頻繁的進行進程間的上下文切換,這樣當併發高時,的機器基本上一定會吃不住。
 圖 2 : 請求太多炸掉圖
圖 2 : 請求太多炸掉圖
資源浪費
花了那麼多的記憶體來建立那麼多個進程,但是它大部份的時間都是在等待 I/O 資料。
 圖 3 : 系統資源浪費圖
圖 3 : 系統資源浪費圖
為什麼需要多個呢 ?
那為什麼每個請求 ( I/O ) 都需要開啟一個進程或線程來處理呢 ?
咱們來看看 http server 它處理請求的運行過程會是如何 ?
它的流程如下圖 4 所示 :
- server process A 的 accept 收到新連線的建立。
- server process A 使用 read 來讀取 client 傳送進來的資料。
- 由於資料還沒進來,所以作業系統進行上下文切換至 process B 來處理工作。
- 有資料進來了,作業系統進行進程上下文切換回 process A。
- server process A 收到 client 的資料。
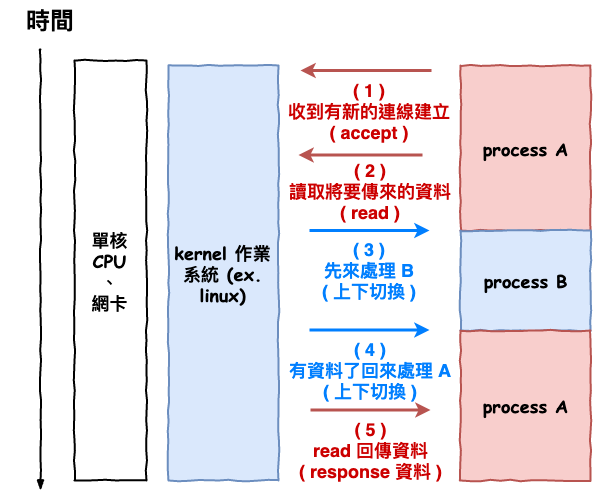 圖 4 : 請求過程
圖 4 : 請求過程
其中問題就出在 2 這個步驟。
data = read(sockfd); // 這裡會阻塞整個 process
handler(data);
為什麼 read 會阻塞呢 ?
咱們根據前幾篇的文章知道,所謂的 I/O 過程如下圖
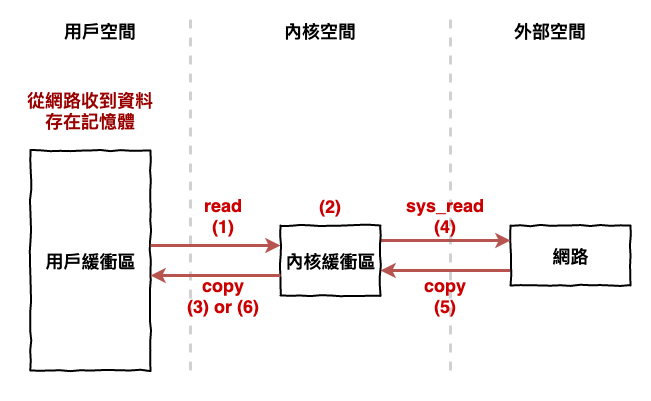 圖 5 : I/O 操作流程
圖 5 : I/O 操作流程
而其中問題就出在內核緩衝區這。以圖 5 範例來看,process A 執行 read 後一開始會看到緩衝區內空空如也,那這裡你覺得它可以做什麼呢 ? 就是只能等待,而這樣就是咱們所謂的『 阻塞 』。
接下來有資料寫到緩衝區後,作業系統會告訴 process A 你觀注的緩衝區有資料囉,可以起來工作了,那這時作業系統就會進行上下文切換的跳回 A 來處理。
這也是為什麼需要開啟每個請求都需要一個進程來處理。
~ 小備註 1 ~ 上述有用到的幾個 system call。
~ 小備註 2 ~
每一個 http 請求基本上就是會建立一條 socket,而 sockfd 又代表此 socket 的 file descriptor,不熟悉網路的友人可以用上面這幾個關鍵字來查詢。
非阻塞 I/O 模式核心 Reactor 模型
由傳統使用多線程或多進程來處理 I/O 有以下兩種缺點 :
- 高併發會爆,因此進程或線程數有限制,且上下文切換。
- 如果應用大部份的服務是 I/O 會很浪費資源(因為就為了等待,而用不少記憶體開進程,但是他大部份都只是在等待)。
因此後來就有人提出了 :
非阻塞 I/O 模式 Reactor
~ 小提醒 ~ 這裡的非阻塞 I/O 是指讓應用層的 I/O 操作,不會阻塞住進程。
reactor 架構
reactor 模式可以幫助我們建立非阻塞 I/O 模式,也就是不需要開多個 thread 或 process 來處理 I/O 操作。
它的概念如下圖 6 所示 :
 圖 6 : reactor 概念圖
圖 6 : reactor 概念圖
上圖架構中,最重要的就是 I/O 多路復用 ( Multiplexing ) 這部份,基本上它是作業系統所提供的功能。多路復用可以幫助我們監控所有有註冊的 socket,當它有事件 ( ex. 可讀資料、有連線時 ) 進來以後,就會由指定的 handler ( callback ) 來進行處理。
下面為 reactor 模式的概念碼。而事實上這就是 nodejs 中我們常聽到的 event loop 的機制。
但這裡要注意,epoll_wait 本身是一個阻塞方法,也就是說執行它時,整個 process 會被卡住。有寫過 nodejs 的人在這裡應該會有疑問,等等會解答。
while(true){
events = epoll_wait(); // 這裡會取得到 I/O 事件
for (int i=0; i < events.size(); i++){
handler(events[i]);
}
}
~ 小備註 ~ : I/O 多路復用 ( Multiplexing ) 不同的平台有不同的實作,epoll ( linux )、kqueue ( Mac )、IOCP ( Window )。
Reactor 模式使用 epoll 的運行範例
在開始說流程直接,咱們先來看首 I/O 多路復用實際上提供的方法有那些,這裡我們以 linux 的 epoll 為範例。
int epoll_create(int size);
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
- epoll_create : 它就是建立一個 epoll 對像,然後它的 size 就是 kernal 保証可以監控的最大 file descitpor 數量。
- epoll_ctl : 它就是將 socket 加入到 epoll 的監控中的方法。
- epoll_wait : 它在給定的 timeout 時間內,如果監控的 socket 有產生事件,則會返回事件。
linux_epoll_create linux_epoll_ctl linux_epoll_wait
下面為我們使用它的範例碼,這個範例的功用就是讓 epoll 監聽你有註冊的 socket,然後當有事件產生時,就可以從 epoll_wait 取得相對應的 socket 與事件,最後再將此事件執行到對應的 event handler。
struct events[10];
// 建立一個 epoll 用 file descriptor
epollfd = epoll_create();
// 註冊讓 epoll 監聽某 socket 的 EPOLLIN 事件(可讀取)
epoll_ctl(epollfd, EPOLL_CTL_ADD, socket, EPOLLIN);
while(true){
// 如果 epoll queue 中有事件產生,則會回傳產生事件的 socket 與 events。
have_events_fds = epoll_wait( epollfd, events, MAX_EVENTS, -1 );
// 讀取每個有產生事件的 socket,並執行對應的 eventHandler。
for(int i=0; i < have_events_fds; i++){
eventHandler(events[n]);
}
}
這裡既然提到 epoll 後,咱們順到來看看它的兩個模式『 LT 』與 『 ET 』
epoll 的 LT 與 ET
上述章節咱們有提到,所謂的『 可以 』讀取資料是指內核緩衝區中有資料後,就可以讀,然後拉到 epoll 這種監聽可不可以讀的場景它多了兩個方案 :
- LT 水平觸發模式 : 只要讀緩衝區不為空,就會一直觸發 read 事件。
- ET 邊緣觸發模式 : 從非空轉為非空的時後觸發一次 read 事件。
在實際咱們在用時預設為 LT 模式。雖然 ET 模式性能較好,但因為 ET 模式可能會漏事件,例如用戶收到 100 個資料,而這時用戶只讀 50 個資料後就不讀,那就沒有下次機會了,因為它只會觸發一次。
一些常見的問題
問題 1 : Multiplexing 與 Handler 是不同的 Process 嗎 ? 還是相同的 ?
答案是都可以。
像 nodejs 就是屬於 multiplexing 與 handler 都是在同一個 process 運行,而 php swoole 則是屬於 multiplexing 與 handler 在不同 process 運行。
在 refactor 中比較常見的組合有以下幾種 :
單個 reactor 進程 ( multiplexing ) + 多個 handler 進程 or 線程
嚴格來說 nodejs 算是屬於這一種,不過它比較特別一點,因為它的 reactor 進程 同時包含一些 handler 工作。
在 nodejs 中它的工作分配如下 :
- reactor 進程 : loop 監聽 epoll,與執行運算的 handler,如果碰到有 I/O 操作,則將它 socket 在丟到 loop 中監聽處理。
- worer thread 線程 : 在 nodejs 中,會將 filesystem 的 I/O 交給此 thread 來處理,以及一些 dns 與加解密或壓縮的運算工作也會丟給它做。
簡單說一下 filesystem 無法丟 epoll 原因在於,epoll 不支援。
EPERM The target file fd does not support epoll.
多個 reactor 進程 ( multiplexing ) + 多個 handler 進程 or 線程
在 php 有名的 swoole 與 java NIO 或 netty 基本上就是屬於此種類型,下圖是 php swoole 的架構。
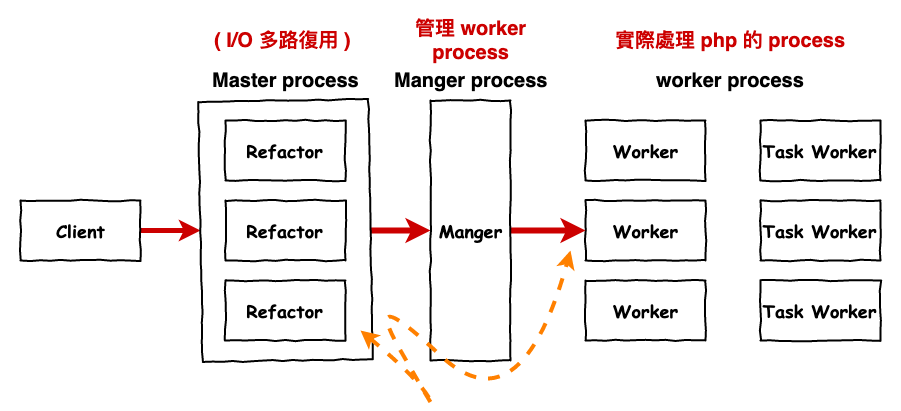 圖 7 : php swooole 架構
圖 7 : php swooole 架構
- Master Process : 用來管理 reactor thread,主要就是當 client 發送一個 http 請求後,由它來決定那個 reactor thread 來接客。
- Reactor Thread : 每個 thead 中都有使用 I/O 多路復用的技術來監聽多個 socket,當有事件(讀或寫資料)進來時,會發送給某個 worker process 來處理。
- Manager Process : 用來管理 worker process,也是用來決定那個 worker process 來接客。
- Worker Process : 實際運行 php 代碼的地方,它這裡也有使用 I/O 多路復用技術來監聽 socket。這裡提供同步阻塞或是異步非阻塞操作。
- Task Process : 一樣 php 代碼運行的地方,它會接受由 worker 丟過來的任務 ( 開發者自已撰寫 ),通常都是一些 cpu 密集的運算。這裡只能同步阻塞操作。
上面簡單的帶過一下,詳細 swoole 可以參考筆者這篇文章。
PHP 的 Web 運行原理 ( 4 ) - Reactor 的實現之 Swoole
基本上這種的優勢在於 :
- 多 reactor 線程或進程,一定可以承受比單線程還多的量。
- CPU 多核的優勢。
問題 2 : Multiplexing 不是需要一個 process 一直監聽所有 socket 嗎 ? 那為什麼 nodejs 可以單個 process 同時做到監聽與處理呢 ?
嗯之前我也有這個疑問。
當初我的想法是如下概念碼一樣,它會在 epoll_wait 阻塞住整個 process 來監聽,然後在有事件時,丟給某個 thread 或其它 process 的 handler 來處理。
while(true){
events = epoll_wait(); // 它會一直停在這裡,等某個 socket 有事件進來。
for (int i=0; i < socket.size(); i++){
handler(events[i])
}
}
epoll_wait 的確是阻塞 I/O 操作沒錯,但是它事實上有提供一個參數 timeout,也就是如果這段時間沒有資料,它就會回傳個 null 或啥 -1 的,反正就是和你說沒資料進來,而這時你就可以繼續往下處理。
備註一下,如果想知道 libvu 所提供的 timeout 計算方式可以拉到最下面參考看看。
while(true){
events = epoll_wait(timeout); // 注意 timeout 。
for (int i=0; i < sockets.size(); i++){
handler(sockets[i])
}
// 取出接下來 event queue 中要處理的工作。
worker = queue.poll();
handler(worker);
}
~ 小備註 ~ 這裡可能有人會提出,nodejs 實際上是另外開 thread 來處理運算工作,然後 event loop process 就是一直在只在做 event loop,但如果真的是這樣你想想,為什麼在 callback 中寫個 while true 所有的工作都無法做了呢 ?
nodejs 的確有偷偷的開 thread 來處理某些工作,但是它只有一些特殊的工作才需要使用 libuv 開的 worker thread 來處理。
詳細的內容可以看看筆者這篇文章。
結論與心得
本篇文章中我們說到以下幾個重點 :
Reactor 模式想解決的問題
大量 I/O 操作的情況,會導致傳統的 I/O 處理模式系統爆掉。
Reactor 架構
重點就是『 I/O 多路復用 』有了它我們才能一個 process 監控多個 socket。
Reactor 的使用注意
在 reactor 模式的系統下,不要執行大量 cpu 運算的工作,會導致整個 process 卡住,大量 cpu 運算請另開 process 或 thread 來處理。
小心得
這裡提一下,在現今軟體世界的語言中,就我所知道的只有 nodejs ( 雖然它不算語言 ) 與 golang 這兩種語言有原生的支援非阻塞 I/O 操作,也就是說你直接使用這個語言所提供的一些 I/O 方法,它們基本上都不會阻塞住整個 process。
但是其它語言就不一定了,例如 php,它是使用一些非阻塞 I/O 的框架,而且重點要使用這框架所提供的非阻塞 I/O 方法,才能變成非阻塞 I/O 系統,詳細 php 的問題可以看看筆者寫的這一篇文章,裡面的『 Swoole 的實際使用注意 』那可以注意一下。
PHP 的 Web 運行原理 ( 4 ) - Reactor 的實現之 Swoole
最後這章節給個三個建議 :
- 當系統 I/O 操作繁重時,請使用 refactor 模式的支援語言或是框架。
- 當系統 CPU 運算繁重時,則使用 multi process 的模式。
- 請知道自已在用什麼東西。
參考資料
- Linux 的 IO 通信 以及 Reactor 线程模型浅析
- Node.js design pattern : Reactor (Event Loop)
- Reactor模式
- 通俗地讲,Netty 能做什么?
- nodejs 异步I/O和事件驱动
- 高性能IO之Reactor模式
- Java NIO 系列文章之 浅析Reactor模式
- 非阻塞IO与reactor模式
- 多路复用、非阻塞、线程与协程
- socket缓冲区以及阻塞模式
- gitbook-libuv
- 我读过的最好的epoll讲解
參考 : libuv 的 timeout 計算
下面為 libuv 的 timeout 計算的方法,
int uv_backend_timeout(const uv_loop_t* loop) {
if (loop->stop_flag != 0)
return 0;
if (!uv__has_active_handles(loop) && !uv__has_active_reqs(loop))
return 0;
if (!QUEUE_EMPTY(&loop->idle_handles))
return 0;
if (!QUEUE_EMPTY(&loop->pending_queue))
return 0;
if (loop->closing_handles)
return 0;
return uv__next_timeout(loop);
}
而下面為 uv__next_timeout 的源始碼。
int uv__next_timeout(const uv_loop_t* loop) {
const struct heap_node* heap_node;
const uv_timer_t* handle;
uint64_t diff;
heap_node = heap_min(timer_heap(loop));
if (heap_node == NULL)
return -1; /* block indefinitely */
handle = container_of(heap_node, uv_timer_t, heap_node);
if (handle->timeout <= loop->time)
return 0;
diff = handle->timeout - loop->time;
if (diff > INT_MAX)
diff = INT_MAX;
return (int) diff;
}