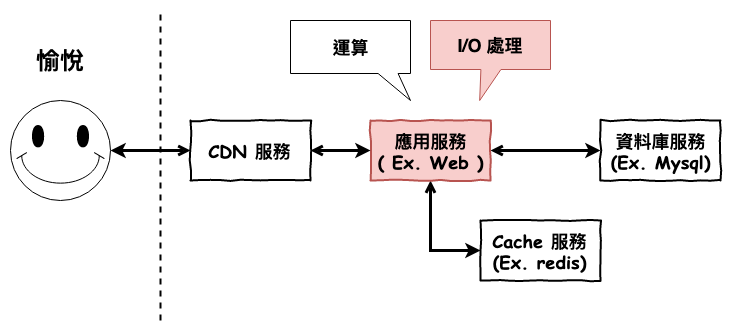
正文開始
上一篇文章說明完了非阻塞 I/O 模式核心 reactor,並且它可以幫我們建立 :
異步非阻塞的 I/O 操作。
而接下這篇文章我們將要來說說 coroutine 協程這東西,協程這東西在 I/O 優化佔據什麼地位呢 ?
簡單的說它可以讓我們實現以下的事情 :
可以在應用層實現同步非阻塞的 I/O 操作
接下來我們來深入的探討一下,協程這東西可以解決什麼事情以下現階段有那些東西有在使用這個機制。本篇文章共分以下幾個章節。
- coroutine 協程想要解決的問題。
- coroutine 協程實現原理。
- Golang 的 goroutine。
coroutine 協程想要解決的問題
首先咱們先來看看它想要解決什麼問題呢 ?
協程它想要將異步非阻塞的 I/O 操作變成同步的。
異步非阻塞寫法
首先咱們來看看 reactor 所實現的異步非阻塞的 I/O 操作的寫法,如下程式碼,這一段是使用 php swoole 來打 redis 的模擬碼。然後重點在於以下兩點 :
- 異步 : callback 機制,也就是下面程式碼裡面的 function。
- 非阻塞 : 當打這個 I/O 操作時,不會阻塞住整個進程。
<?php
$client = new swoole_redis;
$client->connect('127.0.0.1', 6379, function (swoole_redis $client, $result) {
$client->GET('key', 'swoole', function (swoole_redis $client, $result) {
var_dump($result);
});
});
基本上有寫過 js 的一看就知道,這是一種很常見的寫法,而它的問題就在於有可能會有 callback 地獄產生。
而要解決這個問題通常就是以下三個:
- Promise
- Generator
- Coroutines
這裡我們就不深入說明 Promise 與 Generator,而直來說明 Coroutines。
同步非阻塞寫法
由於上面範例 callback 這種寫法在多層有可能會變成 callback hell,因此就有人想說,能不能寫的和一般同步的測試碼一樣,嗯這就是協程誕生的理由。
你使用了協程程式碼就會變成如下,如何是不是好看多與直覺多了呢 ?
<?php
go(function () {
$redis = new Swoole\Coroutine\Redis();
$redis->connect('127.0.0.1', 6379);
$val = $redis->get('key');
});
而事實上在 nodejs 中的 async/await 就是協程。
(async() => {
const client = redis.createClient()
const val = await client.get('key');
})()
Coroutine 協程實現原理
它的實現原理簡單的說就是 :
在應用層所實現一個控制單元
咱們應該都知道 thread 這東東,它的概念就是 cpu 的最小執行單位。也就是說作業系統會以它為單位,將 cpu 分給它。
而協程就是一個更小的執行單位,但是有幾點要注意 :
- 它是純應用端的執行單位,作業系統完全不知道它。
- 它與 thread 一樣都有自已的記憶體空間。
假設作業系統將 CPU 分一段時間給某個 Thread,運行,然後應用端內部會『 自行 』的決定誰先執行,如下圖 1 所示。
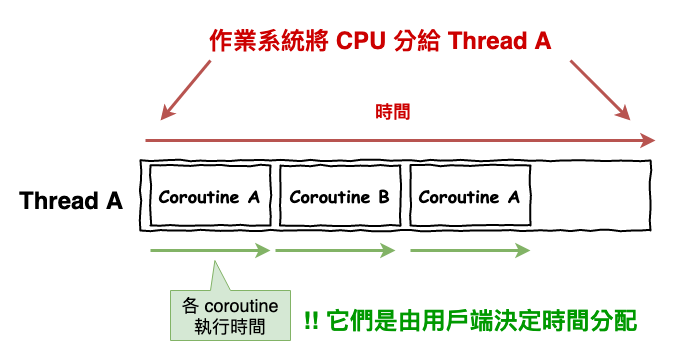 圖 1 : corotuine 的概念圖
圖 1 : corotuine 的概念圖
同步非阻塞 I/O 運行流程
然後當我們知道協程是如何運行後,接下來咱們來看看它是如何搭配非阻塞 I/O 模式。
下圖為當應用端發送一個請求給遠方時的流程。
首先第一張圖 2 是 reactor 運行角度圖,當應用端 corotuine A 發送 http 請求以後,會將此 socket 的 read 事件監控丟給 epoll,然後不斷的去問有沒有資料回來。
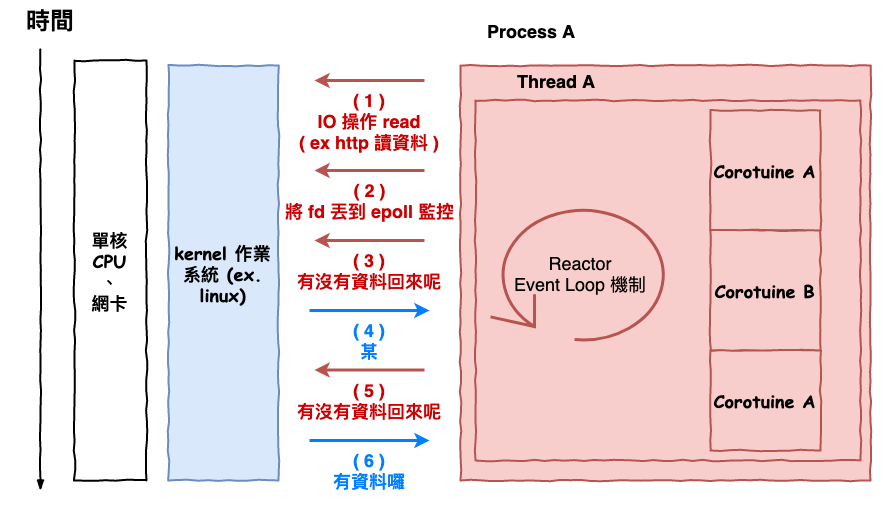 圖 2 : refactor 角度圖
圖 2 : refactor 角度圖
在上述的步驟中,當 corotuine A 丟完 read 後,就會自已讓出控制權,轉成如下圖 3 所示,然後接下來由 corotuine B 開始做它的工作,最後當有請求回應時,在將控制權轉交給 corotuine B,這樣就完了一段請求囉。注意一下,這裡所有的控制都是由『 應用層 』自已處理。
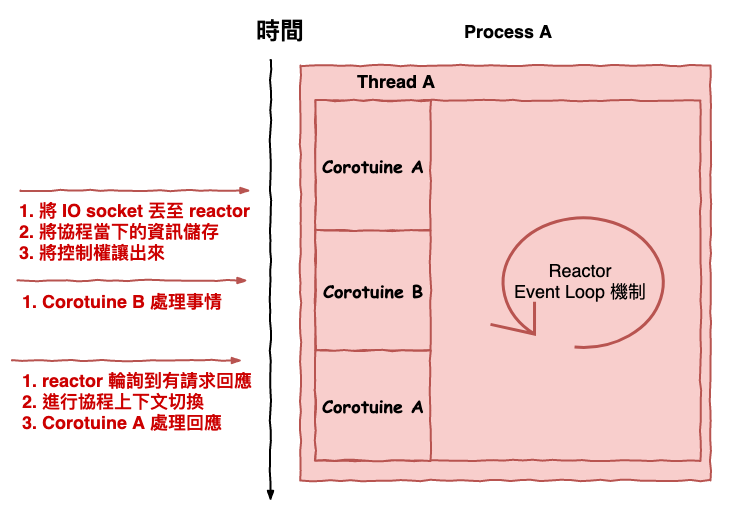 圖 3 : corotuine 角度圖
圖 3 : corotuine 角度圖
關於 Coroutine 的幾個問題
問題 1 : Coroutine 是實現非阻塞 I/O 的技術嗎 ?
不是。
coroutine 很多人會說它是一個比 thread 還更小的操作單位,所以就會想,那我每一個阻塞 I/O 就開一個協程來處理,那這樣不就可以實現非阻塞 i/o 操作了嗎 ? 就像 multi thread 原理一樣,而且我協程更省資源。
nonono ~
process 為作業系統的最小資源管理單位,而 thread 為作業系統最小操作單位。
而 coroutine 是一個比 thread 更小的操作單位,但是它的操作是『應用層』,而不是像 thread 一樣是作業系統所操作。
i/o 的操作是指作業系統的操作,當一個阻塞 i/o 執行時,讓 process 阻塞的是操作系統,所以如果你在一個協程內開啟一個阻塞 i/o 它仍然會卡住整個 process。
coroutine 嚴格來說只能幫你做到同步非阻塞,非阻塞還是需要有 reactor 機制來實現。
問題 2 : coroutine 可以增加性能嗎 ?
不,絕對不是。
它是性能的減項。
它是使用一些資源來將『 異步 』非阻非塞 i/o 操作變成『 同步 』非阻塞 i/o 操作,為了讓寫程式與運行時,是直覺式的一直線運行下來。
然後順到提一下,應該是有不少的文章說 coroutine 適合高 i/o 的應用,這句話只能說一半對一半錯,它有很多前提假設沒給。
你想想,如果它是使用 multi thread 或 multi process 來處理大量 i/o 的情況下,你需要 coroutine 要幹啥 ?
要說 coroutine 適合高 I/O 的應用需要的假設為 :
此應用已是一個異步非阻塞的應用,當你搭配 coroutine 下去,會減少不少的維護成本,因為寫法就和一般程式寫法一樣。
Golang 的 Goroutine
接下來咱們來談談被稱為天生可以支持高併發的 golang,而其中支持它可以高併發的東西稱為 goroutine,很多人說它是 coroutine 事實上有點不太對,但也不能說不對。
接下來咱們來淺淺的來理解一下。
Golang 的運行架構
首先 golang 基本上它的運行架構為所謂的『 MPG 』模型,這個英文字分別代表三個部份 :
- M : 就是 thread,裡面跑了一堆 goroutine。
- P ( Processor ) : 處理器,用來執行 goroutine,然後它裡面要個隊列,裡面放了一堆待處理的 goroutine。
- G ( Goroutine ) : 就是 goroutine 在 golang 中應用端最小的運行單位。
然後它事實上還有第四個重要東西。
- Sched : 嚴格來說它是大總管,它會記錄 M、P、G 的狀態,如果發現某個 M (thread) 工作滿了,就會將一些 goroutine 丟給其它的 M 處理。
上面幾個東西的關連如下圖 4 所示。
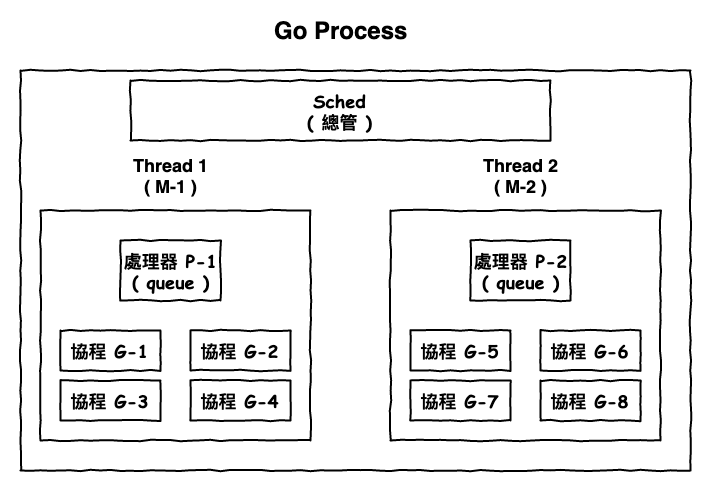 圖 4 : Golang 架構圖
圖 4 : Golang 架構圖
假設一個 goroutine 中有工作要運行,那這時它會被丟到處理器 P 的隊列中排隊處理,然後到它時,就代表這將這個 thread ( M ) 的 cpu 資源分配給它來運行。
那如果 goroutine 在運行時阻塞了怎麼呢 ?
這裡先說一下阻塞的假設。
假設 G-1 這個 goroutine 執行了一些 i/o 請求,又或是在進行大量 cpu 運算,那這時包工頭總管 Sched 將有可能會將,丟到另一個 M 中,有可能是也有可能是開一個 M。
如下圖 5 所示,這圖是另外建立一個新的 M 的說明,當 G-1 這個 goroutine 導致 M-1 這個 thread 無法處理其它資料時,這時總管就會出手,就 M-1 上的所有 goroutine 都移至一個新開的 thread M-3 上面。
然後等到 M-1 上工作解放後,大總管就又會將一些 goroutine 丟回去給 M-1 囉。
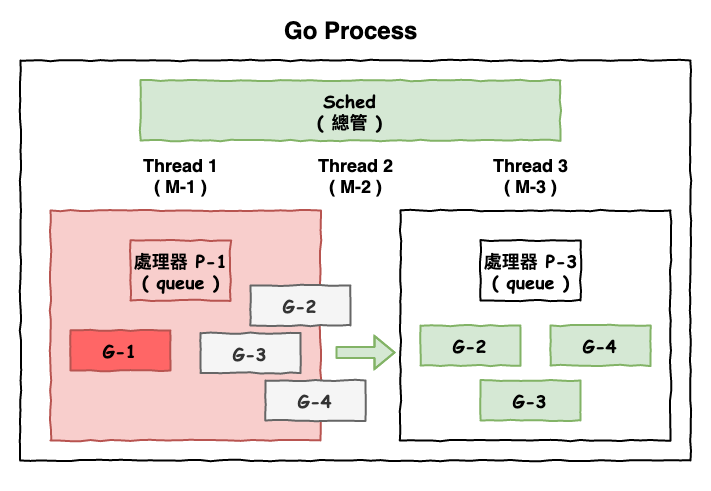 圖 5 : goroutine 工作轉移
圖 5 : goroutine 工作轉移
一些 Goroutine 的問答
問題 1 : goroutine 機制是實現非阻塞 I/O 的機制嗎 ?
不是。
實現非阻塞 I/O 機制的是在 golang 中的 poller 嚴格來說它就是咱們上一章節所說的 refactor 模式。
這裡你想想如果真的是 goroutine 的機制來實現非阻塞 I/O 那會發生什麼事呢 ? 假設一個 goroutine 運行阻塞 i/o 操作,導致某個 thread ( M ) 阻塞,然後剩下的 goroutine 都丟到其它 M 上,假設你只有兩個 M,那第二個 M 在阻塞後,你覺得怎麼辦 ? 再開 M 嗎 ? 那這樣和 multi thread 處理 I/O 有什麼不同 ?
goroutine 這個機制實現的是以下兩個事情 :
- 讓異步非阻塞的 I/O 操作變成同步 ( 就是我們上面說的協程完成的東西 )
- 讓咱們在寫程式不需要『自已寫』開新的 thread 來處理 cpu 運算工作,包在 goroutine 就 ok,因為會自動的分配到閒的 thread。
問題 2 : goroutine 是性能 ++ 項嗎 ?
先說 i/o 這一部份,嚴格來說我覺得是沒有。
就如同上面 corotuine 說的,它只是使用資源來將異步程式碼改成同步程式碼,就算變成 goroutine 看起來也是一樣。
然後 cpu 運算這一塊來說,嚴格來說有一點。
因為傳統上大量 cpu 運法咱們會開多個 thread 來處理,但這裡就要考慮上下文切換的影響,但到了 goroutine 這裡,就有點變成更方便的 thread 池了。
說真的,我真的不覺得 goroutine 是 golang 高性能的核心,不過如果說 golang 高性能的原因被認為是非阻塞 i/o 的話,那我覺得應該是要說高性能核心是因為 goroutine 機制裡面有用到 refactor 才對。
不過也有可能是其它 golang 特性所影響,不然我真的不覺得 goroutine 是高性能的原因。
然後這裡說一下,嚴格來說我沒有對 golang 語言進行到非常深的研究,所以上述只是我的看法,請參考看看就好,對與不對,我不知道,請自行判斷。
問題 3 : goroutine 等於 corotuine
一半算吧,goroutine 有實現 corotuine 想完成的『同步』這個事情,但同時間它又針對 cpu 運算這方面在實現上增加不少改善,讓咱們在運算是只要開 goroutine 就可以取代以前開 thread 來運算的時代,不過它內部的確還是開 thread 沒錯,只是咱們沒感覺。
問題 4 : nodejs 與 golang 相比較
首先以 i/o 處理來看,雙方是戰的差不多的,底層都是使用 refactor 模式,並且在程式碼撰寫上都有提供『 同步 』的處理。
咱來運算方法 golang 說實話真的完勝,golang cpu 運行效率與開發者效率皆優於 nodejs,在寫 golang 時你要進行大量運算只要寫在 goroutine 中就 ok,而在 nodejs 中你則要自已開個 thread 來處理。
說實話,如果後來真的要推薦人開發高性能系統,我還真的會推用 golang,性能或需真的有強點兒,但不是性能的問題,而是用 golang 開發雷人度真的會比較少點。
結論與心得
本篇文章中,咱們學習到了應用層的性能減項 Coroutines,這東西最主要的目的為 :
讓『 異步 』非阻塞 I/O 程式碼,變成『 同步 』。
這個是最重要的核心,這或需不是性能的加項,但是覺得是寫程式碼的加項,應該是有不少人寫過一堆 callback 或 promise 的時代,而後來看到 async/await 這種優雅的程式碼出來,應該愉悅不少,不然原本異步的寫法真的有點混亂與醜。
然後咱們也簡單的理解 golang 的 goroutine 這個機制,目前我看到現在,還是覺得它只完成以下兩件事情 :
- 讓異步非阻塞的 I/O 操作變成同步 ( 就是我們上面說的協程完成的東西 )
- 讓咱們在寫程式不需要『自已寫』開新的 thread 來處理 cpu 運算工作,包在 goroutine 就 ok,因為會自動的分配到閒的 thread。
而非阻塞的 I/O 部份是由 refactor 模式處理。
最後 golang 這部份是對或是錯,就請自行判斷看看,不要別人說是或不是就當順風車,用自已的腦袋從 0 至 1 好好想想看。