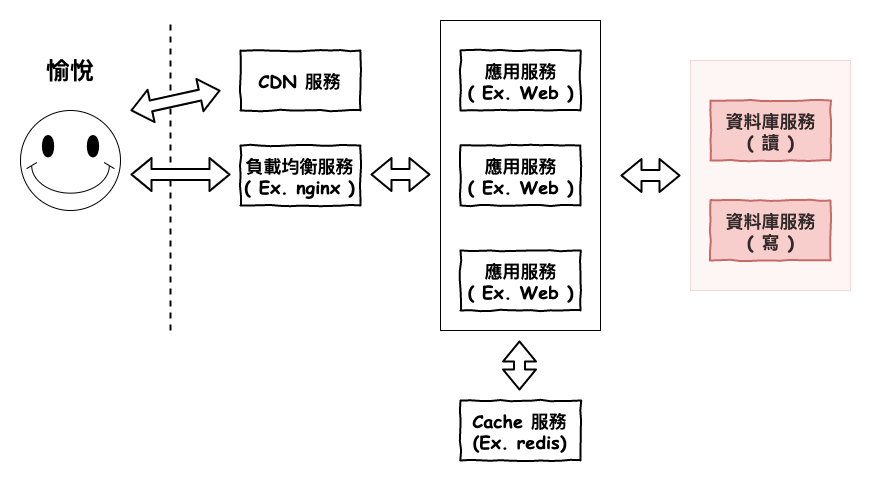
正文開始
前面的文章我們說明完應用層的分散式架構以後,接下來我們要來思考如果讓『 資料庫層 』做更多的事情。
在正式開始章節之前,我們先來想想看一件事情。
資料庫層可以向應用層一樣加機器,就可以做更多的事情嗎 ?
答案為是或不是,這個就取決於使用者的能力,因為假設你沒處理好,不但有可能性能下降,而且導致錯誤百出,它不像應用層那麼簡單的主要原因在於 :
它有狀態的,因為它有儲資料,所有會有一致性問題。
應用層在進行分散式時,基本上都是處於無狀態狀況,所以在進行多台機器時,事實上我們不太需要考慮什麼資料一致的問題,而資料庫則否,當多台時,就要面臨到所謂的資料一致性問題。
接下來的文章與章節我們將要來細說,資料庫層如何的使用分散式架構來讓它做更多的事情,並且有更高的可用性,以及它接下來要面對的種種問題。
本篇文章中,咱們將要先來談談,第一種資料庫層的分散式架構方案『 讀寫分離架構 』:
它適用於讀多寫少情況
本篇文章共分為以下幾個章節 :
- 讀寫分離架構概念
- MySQL 的讀寫分離架構實現
- 可能面臨問題探討
這個分散技術基本上應該是資料庫層分散的第一個起手式,單完成這個架構就已經可以處理不少的事情囉。
資料庫層的讀寫分離架構
基本架構
讀寫分離最簡單的就是所有寫入的都寫入到一台服務,讀取時讀取一台服務,然後你們之間會進行資料同步。
然後在實務上,咱們通常都是會搭配主從架構 ( master-slave ) 來進行讀寫分離。主從架構本來存在的目的是為了可用,就也是如果 master 壞掉了,咱們還有 slave 有資料。
- master : 主要用寫的服務,會與 slave 進行資料同步。
- slave : 主要用來讀的服務
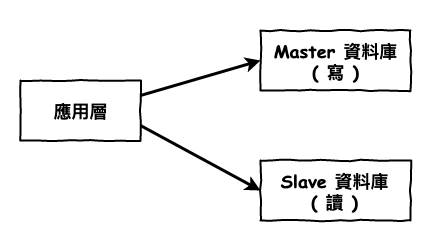 圖 2 : master-slave 實現讀寫概念圖
圖 2 : master-slave 實現讀寫概念圖
讀進化型架構
之前咱們有提過,現在大部份的系統基本上應該是讀大於寫入,所以如果這時只有一台讀,也是有可能會讓它壓力很大,所以這時會變成如圖 3 所示,加個幾台讀機,這種架構被稱為『 一主多從 』。
然後這裡有幾個重點,那就是要如何實現圖 3 的『 分配器 』。
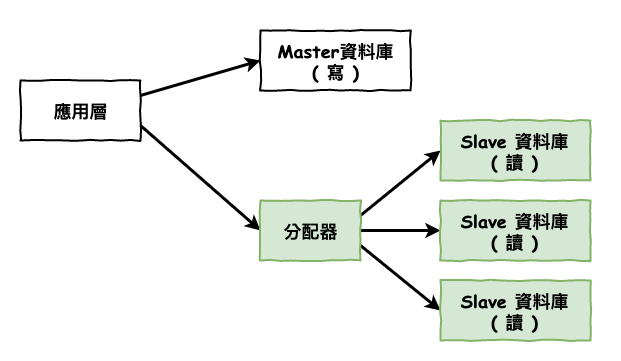 圖 3 : 讀進化型架構圖
圖 3 : 讀進化型架構圖
目前基本上會有以下幾種方案。
分配器的選擇 1 - 負載均衡 ( ex. HA Proxy )
首先第一個是 haproxy,這個東西可以幫我們實現 mysql 的負載均衡,並且如果其中一台 slave 有問題,haproxy 會幫我們停止分配固障那台。
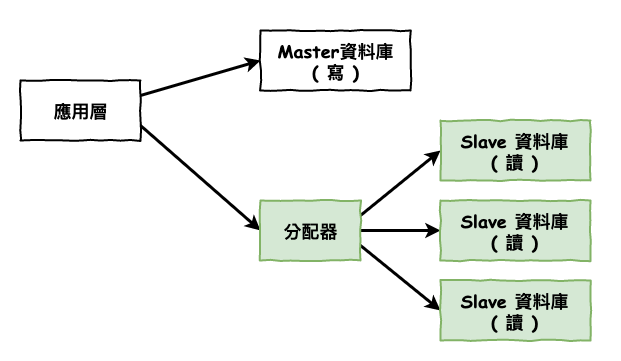 圖 4 : haproxy 架構
圖 4 : haproxy 架構
分配器的選擇 2 - DNS 均衡 ( ex. Consul )
這個也是一個方案,透過 dns 來實現簡單版的負載均衡。
mark-myql-read domain
=> 127.0.0.1:3306
=> 127.0.0.1:3307
=> 128.0.0.1:3308
像使用 consul cluster 就是一個常見的方案,流程如下圖 5 所示。不過這裡簡單說一下 consul 不只可以 dns 發現服務,它事實上也有一些負載均衡的功用,有興趣的可以自已去查查。
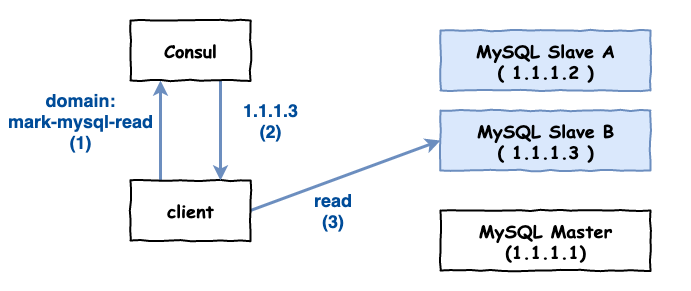 圖 5 : consul
圖 5 : consul
那這裡問個問題 ~ 要如何指定讀 Slave 寫 Master 呢 ?
通常大部份所使用的操作套件都有資源
以 nodejs 來常使用 mysql orm 套件 sequelize,它可以給你進行如下官方範例的設定,當 read 時可以指定讀 slave 那台,當 write 的可以指定寫入那台。
const sequelize = new Sequelize('database', null, null, {
dialect: 'mysql',
port: 3306
replication: {
read: [
{ host: '8.8.8.8', username: 'read-username', password: 'some-password' },
{ host: '9.9.9.9', username: 'another-username', password: null }
],
write: { host: '1.1.1.1', username: 'write-username', password: 'any-password' }
},
pool: { // If you want to override the options used for the read/write pool you can do so here
max: 20,
idle: 30000
},
})
而如果是使用 php laravel 的友人它也有提供相關的設定。
Laravel-Read & Write Connections
'mysql' => [
'read' => [
'host' => '192.168.1.1',
],
'write' => [
'host' => '196.168.1.2'
],
],
根據以上兩種語言套件,事實上咱們真的已經不太需要自已來實現讀寫分離的程式碼了。
MySQL 主從架構實現原理
mysql 基本上實現主從架構資料交換的過程,如下圖 6 所示。
- master 把資料更新寫到 binary log 中。
- slave 將 master 的 binary log 複製到自已的 replay log。
- 讀取 replay log,將資料異動進行更新。
- slave 的 sql thread 去 replay log 拉資料來執行 sql。
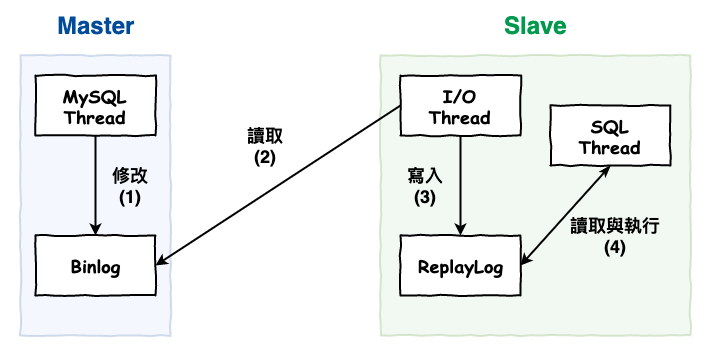 圖 6 : mysql 的主從複製
圖 6 : mysql 的主從複製
~ 小知識 ~ mysql 本身沒有支援所謂的 failover 機制,failover 就是當發現 master 掛掉時,會自動將 slave 升級為 master 來接客的自動化機制。
在 mysql 中需要一些 failover 實現的工具才能使用,例如 MHA ( Master High Availability )、Keepalived、PXC 等,這裡就不多談這些囉。
這裡問個問題 binlog 是什麼呢 ?
它記錄了所有 mysql 資料上的改變,也就是說你只要 insert 或 update 都會記錄在 binlog 中。
但是要注意 binlog 是屬於 mysql 服務層的東西,也就是說不管底層儲存引擎是 inoodb 或 mysiam 啥的,binlog 都是有儲的。
你可以在 mysql 中指令以下指令,來看到 binlog 的事件。
SHOW binlog events;
那 binlog 可以做什麼用呢 ?
- 主從複製
- 資料回復
- 增加備份
- 最終一致性 ( 這在之後會說明 )
三種複制模式
在 mysql 中它有分三種資料從 master 複制到 slave 的模式,至於為什麼有這三個模式,等等下個章節讀寫分離問題那會說。
先說一下這三種模式,會影響到用戶端收到 ack 的時間
複制模式 1 : Async Mode ( 性能優 ) ( 預設 )
預設模式,流程如下圖 7 所示,重點在於 :
master 寫到 binlog 後就回 ack 給 client
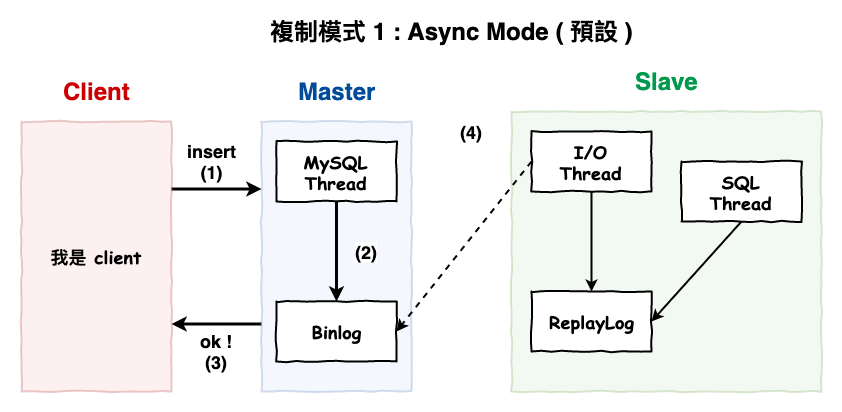 圖 7 : async Mode 模式
圖 7 : async Mode 模式
複制模式 2 : Semi-sync Mode ( 性能中 )
其中一台 slave 寫到 replay log 後,就會回 ack,如下圖 8 所示。這個模式是使用 GTID 所實現,只有在 mysql 5.7+ 以上才支援,這種模式的重點在於 :
寫到其中一台 slave 的 replay log 後,master 才會回 ack 給 client。
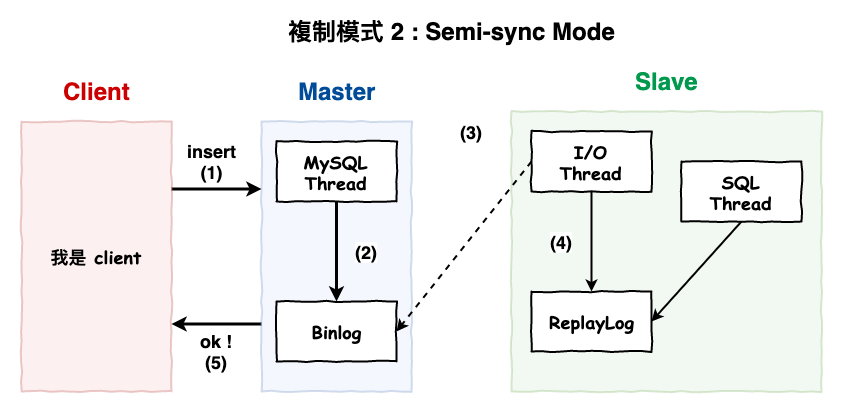 圖 8 : semi-sync Mode 模式
圖 8 : semi-sync Mode 模式
複制模式 3. Sync Mode ( 性能差 )
如下圖 9 所示。這種模式性能最差,但是可以保證所有用戶都讀到相同的資料。
所有 slave 都將資料寫到 replay log 後,master 才會回 ack 給 client,
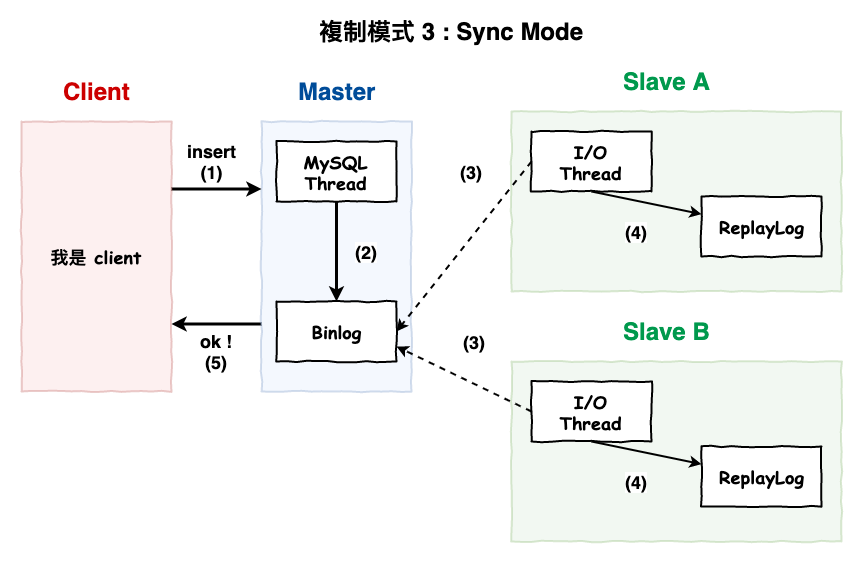 圖 9 : sync Mode 模式
圖 9 : sync Mode 模式
讀寫分離可能面臨問題探討
這種架構可能會碰到什麼問題呢 ?
問題 1 . 主從資料不一致問題
假設咱們有個業務操作如下 :
- 更新 x 資料
- 讀取 x 資料
如下面這張圖 10 所示,當操作 1 執行更新 x 後,執行操作 2 讀取,如果這時還沒主資料庫資料還沒同步到從資料庫,那操作 2 就會讀到舊的資料。
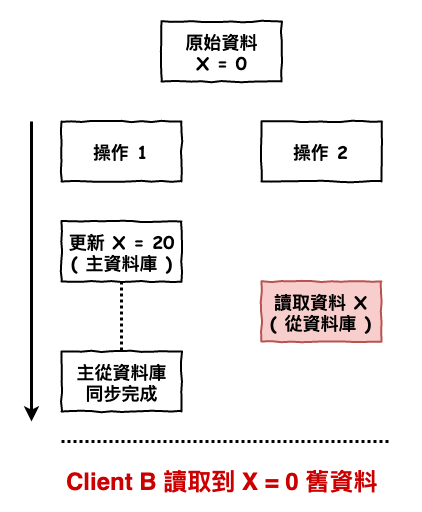 圖 10 : 讀取時可能碰到的問題
圖 10 : 讀取時可能碰到的問題
通常碰到這問題只有以下幾種解法。
解法 1 : 開啟 mysql sync model
也就是說所有的寫入或更新,都需要等到複製完,才能回用戶 ack。但這個性能耗損很嚴重呢。不過還有一種折衷方案就是改成用上述複制模式 2 semi-sync Mode 模式,雖然還是會發生資料不同步的機率,但機率低了不少。
解法 2 : 用戶端寫入後等幾秒再讀
這個方法應該是最常見的手法,我問十個人應該有九個都是用這招。
解法 3 : 應用層中間件動手腳
在一些比較大型的應用上,通常會將架構分成如下 :
用戶 -> 應用層服務 -> 應用層中間件 -> 資料庫服務
其中應用層中間件服務,這個不同公司有不同的定義與實作方法,像咱公司這裡裡面又分為兩塊。
應用層 domain 服務 -> 應用層 model 服務
其中 domain 比較偏向商業定義,而 model 偏向資料庫定義,然後這時咱們會針定一些商業上定義需要完全一致性的操作,強制的讓它讀 master。
這樣的確是有人說,那這樣不就沒有讀寫分離的意義 ? 一半對一半錯,如果只有 10 % 商業服務是需要這種『 完全一致性 』的要求,那也只有 10 % 而以,其它 90 % 還是有讀寫分離。而如果反過 90% 需要的場景,你反而要想那這樣還要搞讀寫分離嗎 ?
問題 2 : 讀寫分離模式與緩存服務不一致問題
根據咱們下述的緩存策略的文章中,咱們的讀策略為 :
先更新 DB 後淘汰緩存
然後咱們接下來和讀寫分離架構合在一起看一下。然後會發現它有問題。
這個問題如下圖 11 過程所示,當操作 1 在淘汰完緩存資料後,且在同步從庫前,有一個讀取進來,那這時它會讀取到舊的資料,並且更新到緩存中。
那這時緩存就會永遠是『 錯 』的資料 ( 除非人為手動回復 )
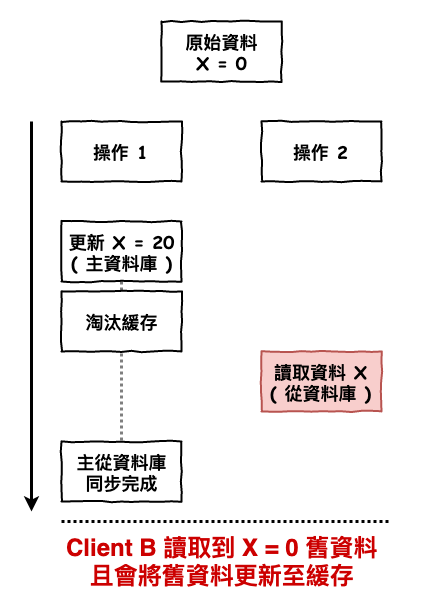 圖 11 : 讀寫分離架構的緩存不一致性問題
圖 11 : 讀寫分離架構的緩存不一致性問題
解法 1 : 多一次讀取
目前查了一下,比較常見的解法如下圖 12 所示,就是在淘汰緩存後,在執行一次讀取,然後強制這次的讀取是讀『 主庫 』,這樣可以有較高的機率回避上述問題。
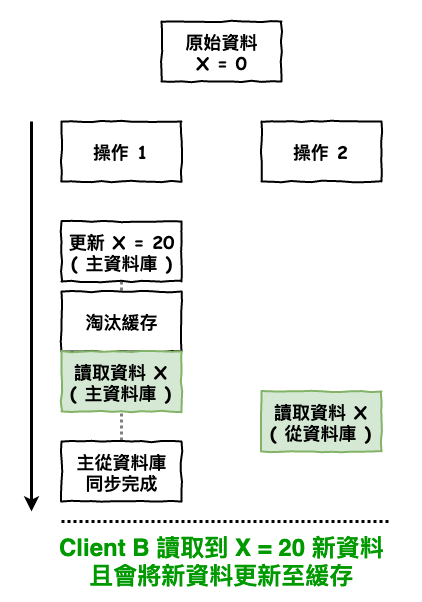 圖 12 : 不一致性問題解法 1
圖 12 : 不一致性問題解法 1
為什麼不要將淘汰緩存,改為更新緩存呢 ?
因為這樣在併發更新時,可能會產生『 緩存永遠是錯的 』可能性,詳細請參考 30-19 的文章。
如果操作 2 的讀取從庫比操作 1 的讀取主庫還前,那不是也有問題嗎 ?
嗯對的,會出問題沒錯,但只能說機率會比較小點兒。
解法 2 : 重複一次操作
就是再重複的進行一下更新操作流程,如下圖 13 所示,就算操作 2 讀取時將舊資料更新的緩存後,這個錯誤的操作會被第二次更新時洗掉,除非你真運氣差到兩次都碰上,不然這個出問題的機率應該是非常非常的低。
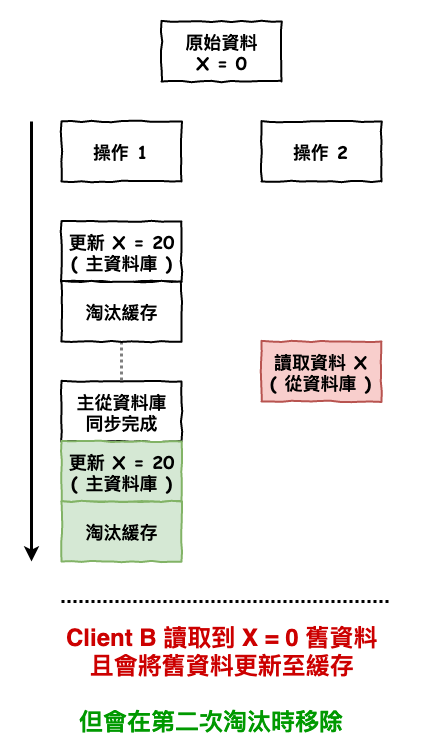 圖 13 : 不一致問題解法 2
圖 13 : 不一致問題解法 2
可能解法 3 : binlog 訂閱
先說一下,我不確定這個方法可不可以解決,這只是提出來參考兩下的。
目前網路上有提供一些工具,它可以監控 binlog 的變化,來更新緩存服務,例如阿里八八開發的這個工具。
但是有沒有什麼雷我就不知道了,之後應該會來深入的研究兩下。
結論與心得
本篇文章咱們探討了資料庫擴展的第一個起手式 :
讀寫分離架構
然後在 mysql 中基本上它是以主從架構來實現,然後它實現兩台資料庫資料同步的方法主要是依賴於 binlog 上,而其中它的整個複制的模式,也影響了用戶收到回應時間速度。
- 複制模式 1 : Async Mode ( 性能優 ) ( 預設 )
- 複制模式 2 : Semi-sync Mode ( 性能中 )
- 複制模式 3. Sync Mode ( 性能差 )
最後咱們討論了讀寫分離的以下兩個問題 :
- 主從資料不一致問題
- 讀寫分離模式與緩存服務不一致問題
上述兩個問題說實話,都沒完美解,這或許就是追求性能的路上必然之路。
一致性難題
這也是為啥會建議,沒必要,真的別搞分散式,你真的會被一致性難題搞的心力交瘁,如果沒問題,你先想想有沒有可能能事實上量很小到產生不了問題呢 ?